")
Descriptions
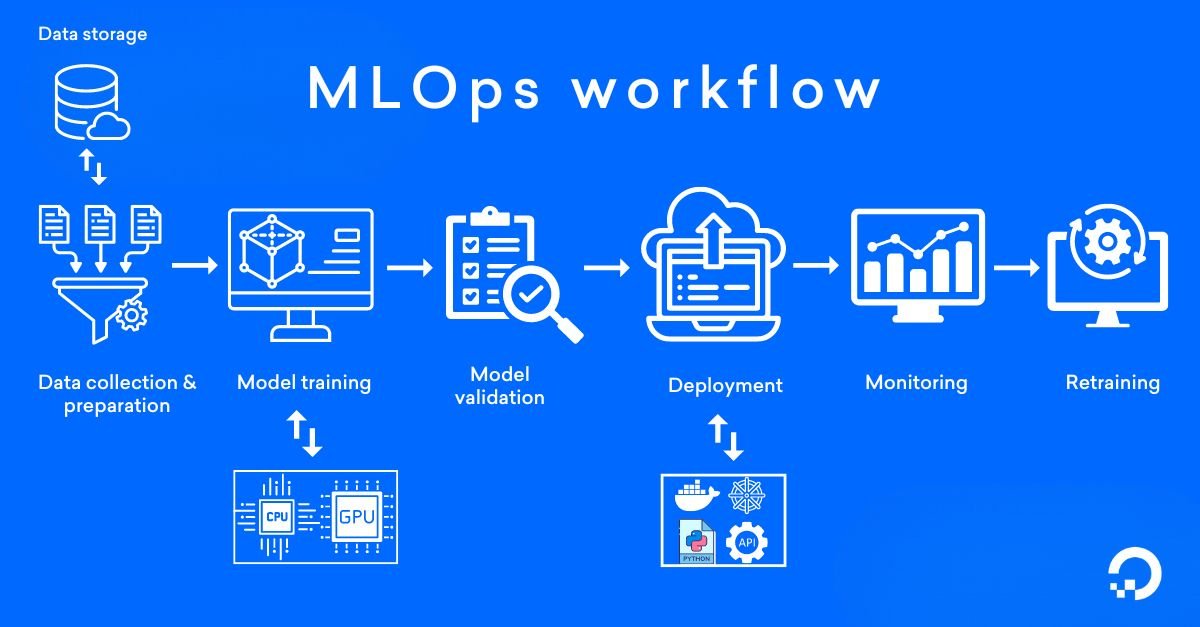
Fine-tune an open-source LLM (e.g., Llama 3) on a proprietary corpus of medical texts to improve its accuracy and relevance for clinical query responses.
Skills
Frequently Asked Questions
Is the fine-tuning data corpus already prepared?
Yes, a clean, labeled dataset of 10GB of proprietary text will be provided.
Will the client provide the necessary GPU resources?
Yes, the client will grant temporary, secure access to a dedicated cloud-based GPU instance.